
The use of specialized processors such as GPUs (Graphics Processing Units), NPUs (Neural Processing Units), or DSPs (Digital Signal Processors) for hardware acceleration can significantly enhance the performance of inference tasks in ML-enabled Android applications.
These specialized processors are designed to handle the computational demands of ML tasks more efficiently than general-purpose CPUs (Central Processing Units), leading to faster inference times and a better user experience.
The challenge lies in the diversity of hardware and drivers across different user devices. Each device may have different capabilities and optimal configurations for running ML models, making it difficult to choose the best hardware acceleration setup. Selecting an inappropriate configuration can lead to suboptimal performance, high latency, and even runtime errors or accuracy issues due to hardware incompatibilities. This can degrade the user experience and negate the benefits of hardware acceleration. Writing programs to use hardware like GPUs/NPUs/DSPs/FPGAs along with the CPU falls under the programming paradigm of heterogenous computing.
Acceleration Service for Android
The Acceleration Service for Android is an API designed to address these challenges by helping developers automatically select the optimal hardware acceleration configuration for each user’s device. This service evaluates various acceleration configurations by running internal benchmarks with the provided TensorFlow Lite (TFLite) model on the user’s device. These test runs typically complete in a few seconds, depending on your model. You can run the benchmarks once on every user device before inference time, cache the result and use it during inference.
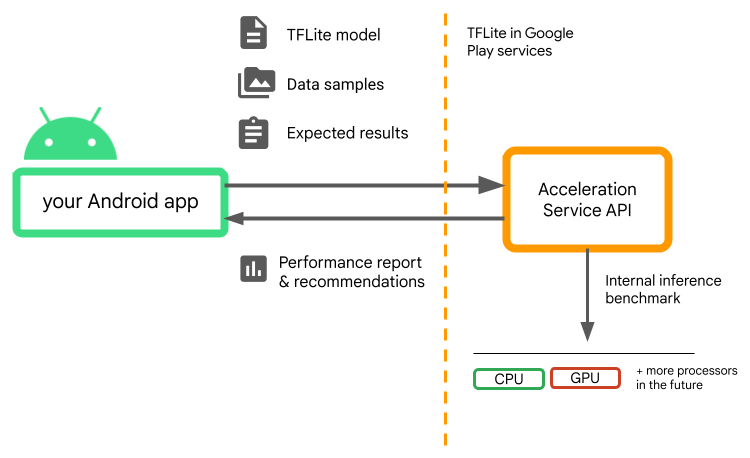
These benchmarks are run out-of-process; which minimizes the risk of crashes to your app. By leveraging the Acceleration Service, developers can ensure that their ML-enabled applications perform optimally across a wide range of devices, enhancing user experience while minimizing the risk of runtime errors and maintaining model accuracy. This service abstracts the complexity of hardware variability and provides a streamlined approach to optimizing inference performance on Android devices.
You can check out the API documentation for detailed usage1
- GPU Acceleration Delegate with Java/Kotlin Interpreter API. TensorFlow Lite Documentation. (Accessed: 16 June 2024) ↩︎












Leave a comment